先看再点赞,给自己一点思考的时间,微信搜索【沉默王二】关注这个有颜值却假装靠才华苟且的程序员。 本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我的系列文章。
List 系列差不多写完了, 单线程环境下最重要的就是 ArrayList 和 LinkedList,多线程环境下最重要的就是 CopyOnWriteArrayList,新来的同学可以点击链接回顾一下 List 的知识点。接下来,我要带着 HashMap 去爬山了,注意不是六峰山,纯粹就是为了锻炼了一下身体,不不不,纯粹是为了和 HashMap 拉近关系,同学们注意不要掉队。
说一句很废的话,HashMap 是一个 Map,用来存储 key-value 的键值对,每个键都可以精确地映射到一个值,然后我们可以通过这个键快速地找到对应的值。
对于一个 List 来说,如果要找到一个值,时间复杂度为 $O(n)$,如果 List 排序过的话,时间复杂度可以降低到 $O(log n)$(二分查找法),但如果是 Map 的话,大多数情况下,时间复杂度能够降低到 $O(1)$。
来看一下 HashMap 的特点:
-
HashMap 的键必须是唯一的,不能重复。
-
HashMap 的键允许为 null,但只能有一个这样的键;值可以有多个 null。
-
HashMap 是无序的,它不保证元素的任何特定顺序。
-
HashMap 不是线程安全的;多线程环境下,建议使用 ConcurrentHashMap,或者使用
Collections.synchronizedMap(hashMap)将 HashMap 转成线程同步的。 -
只能使用关联的键来获取值。
-
HashMap 只能存储对象,所以基本数据类型应该使用其包装器类型,比如说 int 应该为 Integer。
-
HashMap 实现了 Cloneable 和 Serializable 接口,因此可以拷贝和序列化。
01、HashMap 的重要字段
HashMap 有 5 个非常重要的字段,我们来了解一下。(JDK 版本为 14)
transient Node<K,V>[] table;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
1)table 是一个 Node 类型的数组,默认长度为 16,在第一次执行 resize() 方法的时候初始化。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
final HashMap.Node<K,V>[] resize() {
newCap = DEFAULT_INITIAL_CAPACITY;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
}
Node 是 HashMap 的一个内部类,实现了 Map.Entry 接口,本质上是一个键值对。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
HashMap.Node<K,V> next;
Node(int hash, K key, V value, HashMap.Node<K,V> next) {
...
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
...
}
public final V setValue(V newValue) {
...
}
public final boolean equals(Object o) {
...
}
}
2)size 就是 HashMap 中实际存储的键值对数量,它和 table 的 length 是有区别的。
为了说明这一点,我们来看下面这段代码:
HashMap<String,Integer> map = new HashMap<>();
map.put("1", 1);
声明一个 HashMap,然后 put 一个键值对。在 put() 方法处打一个断点后进入,等到该方法临近结束的时候加一个 watch(table.length),然后就可以观察到如下结果。

也就是说,数组的大小为 16,但 HashMap 的大小为 1。
3)modCount 主要用来记录 HashMap 实际操作的次数,以便迭代器在执行 remove() 等操作的时候快速抛出 ConcurrentModificationException,因为 HashMap 和 ArrayList 一样,也是 fail-fast 的。
关于 ConcurrentModificationException 的更多信息,请点击下面的链接查看 03 小节的内容。
4)threshold 用来判断 HashMap 所能容纳的最大键值对数量,它的值等于数组大小 * 负载因子。默认情况下为 12(16 * 0.75),也就是第一次执行 resize() 方法的时候。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
final HashMap.Node<K,V>[] resize() {
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
5)loadFactor 为负载因子,默认的 0.75 是对空间和时间效率上的一个平衡选择,一般不建议修改,像我这种工作了十多年的老菜鸟,就从来没有修改过这个值。
02、HashMap 的 hash 算法
Hash,一般译作“散列”,也有直接音译为“哈希”的,这玩意什么意思呢?就是把任意长度的数据通过一种算法映射到固定长度的域上(散列值)。
再直观一点,就是对一串数据 wang 进行杂糅,输出另外一段固定长度的数据 er——作为数据 wang 的特征。我们通常用一串指纹来映射某一个人,别小瞧手指头那么大点的指纹,在你所处的范围内很难找出第二个和你相同的(人的散列算法也好厉害,有没有?)。
对于任意两个不同的数据块,其散列值相同的可能性极小,也就是说,对于一个给定的数据块,找到和它散列值相同的数据块极为困难。再者,对于一个数据块,哪怕只改动它的一个比特位,其散列值的改动也会非常的大——这正是 Hash 存在的价值!
同学们已经知道了,HashMap 的底层数据结构是一个数组,那不管是增加、删除,还是查找键值对,定位到数组的下标非常关键。
那 HashMap 是通过什么样的方法来定位下标呢?
第一步,hash() 方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
第二步,putVal() 方法中的一行代码:
n = (tab = resize()).length;
i = (n - 1) & hash;
为了更容易理解,我把这两步的方法合并到了一起:
String [] keys = {"沉","默","王","二"};
for (String k : keys) {
int hasCode = k.hashCode();
int right = hasCode >>> 16;
int hash = hasCode ^ right;
int i = (16 - 1) & hash;
System.out.println(hash + " 下标:" + i);
}
1)k.hashCode() 用来计算键的 hashCode 值。对于任意给定的对象,只要它的 hashCode() 返回值是相同,那么 hash() 方法计算得到的 Hash 码就总是相同的。
要能够做到这一点,就要求作为键的对象必须是不可变的,并且 hashCode() 方法要足够的巧妙,能够最大可能返回不重复的 hashCode 值,比如说 String 类。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
2)>>> 为无符号右移运算符,高位补 0,移多少位补多少个 0。
3)^ 为异或运算符,其运算规则为 1^0 = 1、1^1 = 0、0^1 = 1、0^0 = 0。
4)& 为按位与运算符,运算规则是将两边的数转换为二进制位,然后运算最终值,运算规则即(两个为真才为真)1&1=1、1&0=0、0&1=0、0&0=0。
关于 >>>、^、& 运算符,涉及到二进制,本篇文章不再深入研究,感兴趣的同学可以自行研究一下。
假如四个字符串分别是”沉”,”默”,”王”,”二”,它们通过 hash() 方法计算后值和下标如下所示:
27785 下标:9
40664 下标:8
29579 下标:11
20108 下标:12
应该说,这样的 hash 算法非常巧妙,尤其是第二步。
HashMap 底层数组的长度总是 2 的 n 次方,当 length 总是 2 的 n 次方时,
(length - 1) & hash运算等价于对数组的长度取模,也就是hash%length,但是 & 比 % 具有更高的效率。
03、HashMap 的 put() 方法
HashMap 的 hash 算法我们是明白了,但似乎有一丝疑虑,就是万一计算后的 hash 值冲突了怎么办?
比如说,“沉X”计算后的 hash 值为 27785,其下标为 9,放在了数组下标为 9 的位置上;过了一会,又来个“沉Y”计算后的 hash 值也为 27785,下标也为 9,也需要放在下标为 9 的位置上,该怎么办?
为了模拟这种情况,我们来新建一个自定义的键类。
public class Key {
private final String value;
public Key(String value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Key key = (Key) o;
return value.equals(key.value);
}
@Override
public int hashCode() {
if (value.startsWith("沉")) {
return "沉".hashCode();
}
return value.hashCode();
}
}
在 hashCode() 方法中,加了一个判断,如果键是以“沉”开头的话,就返回“沉”的 hashCode 值,这就意味着“沉X”和“沉Y”将会出现在数组的同一个下标上。
HashMap<Key,String> map = new HashMap<>();
map.put(new Key("沉X"),"沉默王二X");
map.put(new Key("沉Y"),"沉默王二Y");
那紧接着来看一下 put() 方法的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
put() 方法会先调用 hash() 方法计算 key 的 hash 值,然后再调用内部方法 putVal():
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
// ①、数组 table 为 null 时,调用 resize 方法创建默认大小的数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// ②、计算下标,如果该位置上没有值,则填充
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
HashMap.Node<K,V> e; K k;
// ③、如果键已经存在了,并且 hash 值相同,直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// ④、红黑树处理
else if (p instanceof HashMap.TreeNode)
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// ⑤、增加链表来处理哈希冲突
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表长度大于 8 转换为红黑树处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果键已经存在了,并且 hash 值相同,直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// ⑥、超过容量限制,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
代码里我加了一些注释,同学们一定要花点时间看一下。
如果哈希冲突的话,会执行 ② 处对应的 else 语句,先判断键是否相等,相等的话直接覆盖;否则执行 ④,做红黑树处理;如果不是,会执行 ⑤,把上一个节点的 next 赋值为新的 Node。
也就是说,如果哈希冲突了,会在数组的同一个位置上增加链表,如果链表的长度大于 8,将会转化成红黑树进行处理。
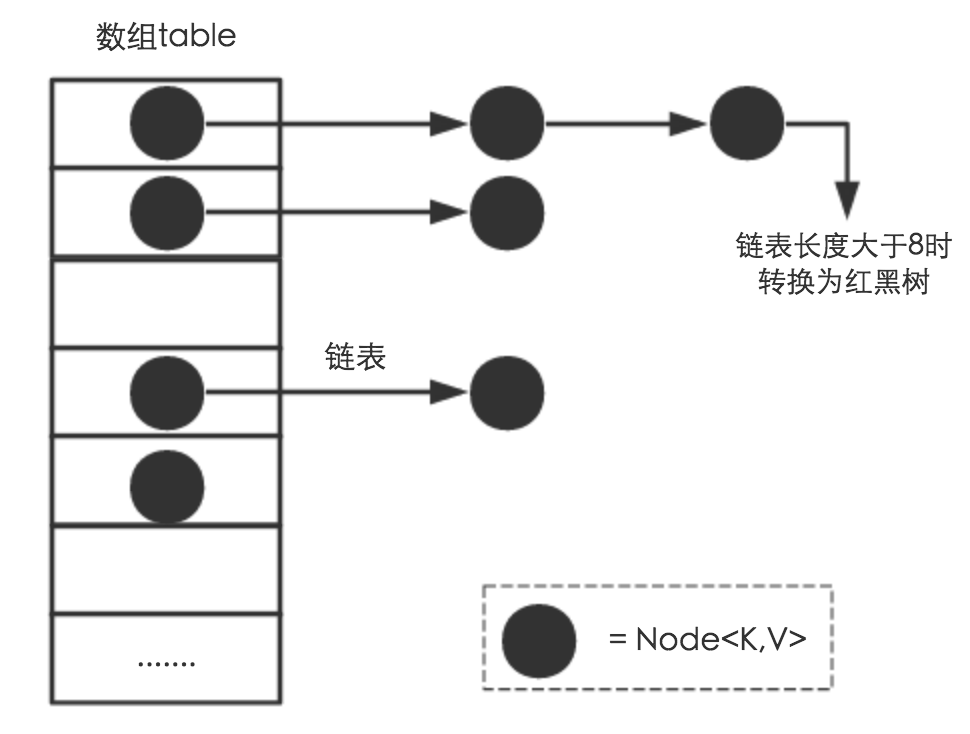
以上就是大牛们嘴里常说的“链地址法”,简单点说,就是数组加链表,由于链表的查询效率比较低(时间复杂度为 $O(n)$),Java 8 又追加了红黑树(时间复杂度为 $O(log n)$)。
留个小作业哈,同学们可以研究一下,当键为 null 的时候,键值对存放在什么位置上?
04、HashMap 的 get() 方法
理解了 HashMap 的 hash 算法和 put() 方法,get() 方法就很容易理解。
public V get(Object key) {
HashMap.Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
首先计算 key 的 hash 值,当 hash 值确定后,键值对在数组中的下标位置也就确定了,然后再调用 getNode() 方法:
final HashMap.Node<K,V> getNode(int hash, Object key) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof HashMap.TreeNode)
return ((HashMap.TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
其中 first = tab[(n - 1) & hash] 就可以快速的确定键对应的值,如果键相等并且键的 hash 相等,则直接返回;如果键的哈希冲突了,就先判断是不是红黑树,不是的话就遍历链表。
05、最后
说句实在话,在写这篇文章之前,我对 HashMap 的认知并没有这么深刻,但写完这篇文章后,我敢拍着胸脯信誓旦旦地说:“HashMap 我真的掌握了,同学们谁以后再问我,就可以把这篇文章甩给他了。”
这次爬山虽然很累,但确实收获很大,值了!
我是沉默王二,一枚有颜值却假装靠才华苟且的程序员。关注即可提升学习效率,别忘了三连啊,点赞、收藏、留言,我不挑,奥利给🌹。
注:如果文章有任何问题,欢迎毫不留情地指正。
如果你觉得文章对你有些帮助,欢迎微信搜索「沉默王二」第一时间阅读,回复关键字「小白」可以免费获取我肝了 4 万+字的 《Java 小白从入门到放肆》2.0 版;本文 GitHub github.com/itwanger 已收录,欢迎 star。

(转载本站文章请注明作者和出处 沉默王二)