先看再点赞,给自己一点思考的时间,微信搜索【沉默王二】关注这个有颜值却假装靠才华苟且的程序员。 本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题。
吃饭间隙,迷上了《吐槽大会》,一集一集地刷啊,觉得这些嘉宾真的挺有勇气的,敢于直面自己的惨淡槽点。于是,同学们看到了,我作为一个技术博主,也受到了“传染”,不,受到了“熏陶”,本来这篇文章标题就想叫《TreeMap 指南》,是不是有点平淡无奇,没有槽点?于是我就想,不妨蹭点吐槽大会的热度吧,虽然吐槽大会现在也没什么热度了哈。
TreeMap,虽然也是个 Map,但存在感太低了。我做程序员这十多年里,HashMap 用了超过十年,TreeMap 只用了多字里那么一小会儿一小会儿,真的是,太惨了。
虽然 TreeMap 用得少,但还是有用处的。
之前 LinkedHashMap 那篇文章里提到过了,HashMap 是无序的,所有有了 LinkedHashMap,加上了双向链表后,就可以保持元素的插入顺序和访问顺序,那 TreeMap 呢?
TreeMap 由红黑树实现,可以保持元素的自然顺序,或者实现了 Comparator 接口的自定义顺序。
可能有些同学不知道红黑树,理解起来 TreeMap 就有点难度,那我先来普及一下:
红黑树(英语:Red–black tree)是一种自平衡的二叉查找树(Binary Search Tree),结构复杂,但却有着良好的性能,完成查找、插入和删除的时间复杂度均为 log(n)。
二叉查找树又是什么呢?
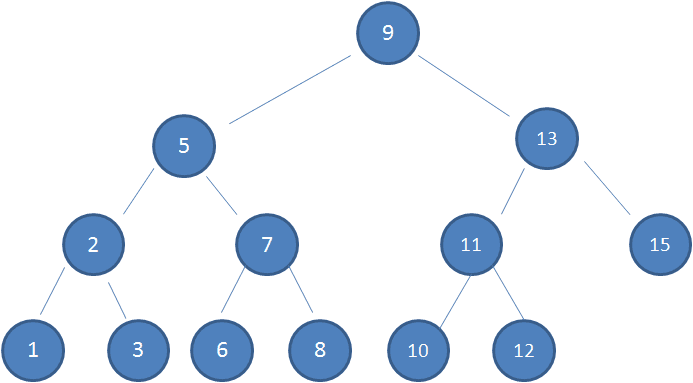
上图中这棵树,就是一颗典型的二叉查找树:
1)左子树上所有节点的值均小于或等于它的根结点的值。
2)右子树上所有节点的值均大于或等于它的根结点的值。
3)左、右子树也分别为二叉排序树。
理解二叉查找树了吧?不过,二叉查找树有一个不足,就是容易变成瘸子,就是一侧多,一侧少,就像下图这样:
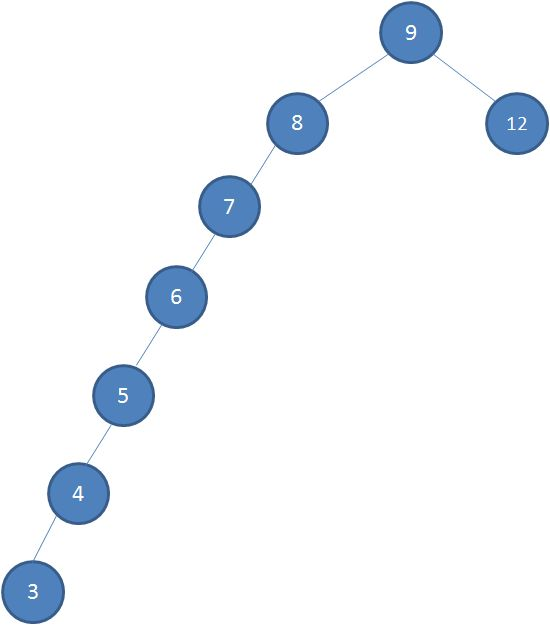
查找的效率就要从 log(n) 变成 o(n) 了,对吧?必须要平衡一下,对吧?于是就有了平衡二叉树,左右两个子树的高度差的绝对值不超过 1,就像下图这样:
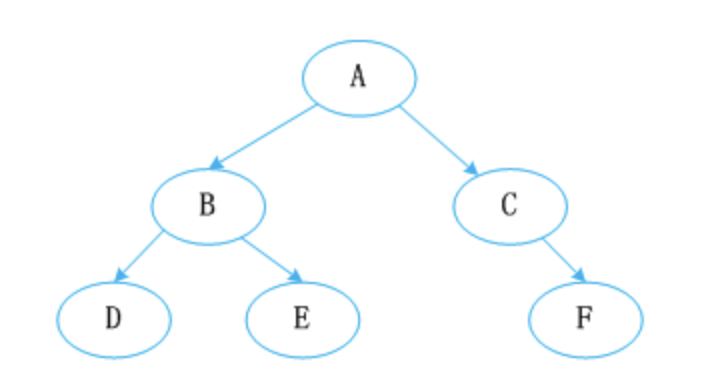
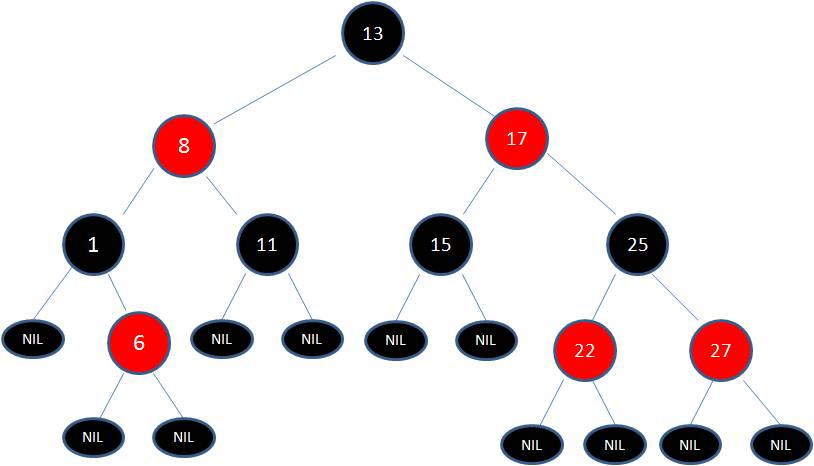
红黑树,顾名思义,就是节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡:
1)每个节点都只能是红色或者黑色
2)根节点是黑色
3)每个叶节点(NIL 节点,空节点)是黑色的。
4)如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
那,关于红黑树,同学们就先了解到这,脑子里有个大概的印象,知道 TreeMap 是个什么玩意。
01、自然顺序
默认情况下,TreeMap 是根据 key 的自然顺序排列的。比如说整数,就是升序,1、2、3、4、5。
TreeMap<Integer,String> mapInt = new TreeMap<>();
mapInt.put(3, "沉默王二");
mapInt.put(2, "沉默王二");
mapInt.put(1, "沉默王二");
mapInt.put(5, "沉默王二");
mapInt.put(4, "沉默王二");
System.out.println(mapInt);
输出结果如下所示:
{1=沉默王二, 2=沉默王二, 3=沉默王二, 4=沉默王二, 5=沉默王二}
TreeMap 是怎么做到的呢?想一探究竟,就得上源码了,来看 TreeMap 的 put() 方法(省去了一部分,版本为 JDK 14):
public V put(K key, V value) {
TreeMap.Entry<K,V> t = root;
int cmp;
TreeMap.Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
}
else {
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
return null;
}
注意 cmp = k.compareTo(t.key) 这行代码,就是用来进行 key 的比较的,由于此时 key 是 int,所以就会调用 Integer 类的 compareTo() 方法进行比较。
public int compareTo(Integer anotherInteger) {
return compare(this.value, anotherInteger.value);
}
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
那相应的,如果 key 是字符串的话,也就会调用 String 类的 compareTo() 方法进行比较。
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
byte coder = coder();
if (coder == anotherString.coder()) {
return coder == LATIN1 ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}
由于内部是由字符串的字节数组的字符进行比较的,是不是听起来很绕?对,就是很绕,所以使用中文字符串作为 key 的话,看不出来效果。
TreeMap<String,String> mapString = new TreeMap<>();
mapString.put("c", "沉默王二");
mapString.put("b", "沉默王二");
mapString.put("a", "沉默王二");
mapString.put("e", "沉默王二");
mapString.put("d", "沉默王二");
System.out.println(mapString);
输出结果如下所示:
{a=沉默王二, b=沉默王二, c=沉默王二, d=沉默王二, e=沉默王二}
字母的升序,对吧?
02、自定义排序
如果自然顺序不满足,那就可以在声明 TreeMap 对象的时候指定排序规则。
TreeMap<Integer,String> mapIntReverse = new TreeMap<>(Comparator.reverseOrder());
mapIntReverse.put(3, "沉默王二");
mapIntReverse.put(2, "沉默王二");
mapIntReverse.put(1, "沉默王二");
mapIntReverse.put(5, "沉默王二");
mapIntReverse.put(4, "沉默王二");
System.out.println(mapIntReverse);
TreeMap 提供了可以指定排序规则的构造方法:
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
Comparator.reverseOrder() 返回的是 ReverseComparator 对象,就是用来反转顺序的,非常方便。
所以,输出结果如下所示:
{5=沉默王二, 4=沉默王二, 3=沉默王二, 2=沉默王二, 1=沉默王二}
HashMap 是无序的,插入的顺序随着元素的增加会不停地变动。但 TreeMap 能够至始至终按照指定的顺序排列,这对于需要自定义排序的场景,实在是太有用了!
03、排序的好处
既然 TreeMap 的元素是经过排序的,那找出最大的那个,最小的那个,或者找出所有大于或者小于某个值的键来说,就方便多了。
Integer highestKey = mapInt.lastKey();
Integer lowestKey = mapInt.firstKey();
Set<Integer> keysLessThan3 = mapInt.headMap(3).keySet();
Set<Integer> keysGreaterThanEqTo3 = mapInt.tailMap(3).keySet();
System.out.println(highestKey);
System.out.println(lowestKey);
System.out.println(keysLessThan3);
System.out.println(keysGreaterThanEqTo3);
TreeMap 考虑得很周全,恰好就提供了 lastKey()、firstKey() 这样获取最后一个 key 和第一个 key 的方法。
headMap() 获取的是到指定 key 之前的 key;tailMap() 获取的是指定 key 之后的 key(包括指定 key)。
来看一下输出结果:
5
1
[1, 2]
[3, 4, 5]
04、如何选择 Map
在学习 TreeMap 之前,我们已经学习了 HashMap 和 LinkedHashMap ,那如何从它们三个中间选择呢?
HashMap、LinkedHashMap、TreeMap 都实现了 Map 接口,并提供了几乎相同的功能(增删改查)。它们之间最大的区别就在于元素的顺序:
HashMap 完全不保证元素的顺序,添加了新的元素,之前的顺序可能完全逆转。
LinkedHashMap 默认会保持元素的插入顺序。
TreeMap 默认会保持 key 的自然顺序(根据 compareTo() 方法)。
来个表格吧,一目了然。
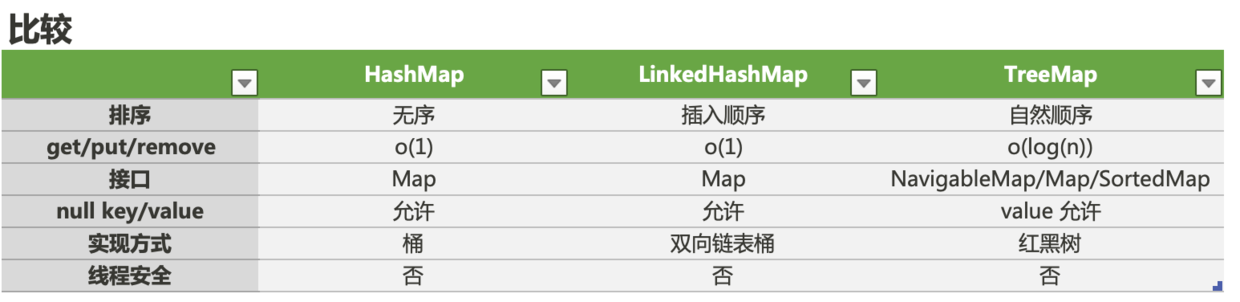
谢谢大家,下期见,同学们。
我是沉默王二,一枚有颜值却假装靠才华苟且的程序员。关注即可提升学习效率,别忘了三连啊,点赞、收藏、留言,我不挑,奥利给🌹。
注:如果文章有任何问题,欢迎毫不留情地指正。
如果你觉得文章对你有些帮助,欢迎微信搜索「沉默王二」第一时间阅读,回复关键字「小白」可以免费获取我肝了 4 万+字的 《Java 小白从入门到放肆》2.0 版;本文 GitHub github.com/itwanger 已收录,欢迎 star。

(转载本站文章请注明作者和出处 沉默王二)