本篇通过一种趣味化的形式来讲述 Java 的集合。
00、故事的起源
“二哥,上一篇《泛型》的反响效果怎么样啊?”三妹对她提议的《教妹学 Java》专栏很是关心。
“有人评论说,‘二哥你敲代码都敲出幻想了啊。’”
“呵呵,这句话充斥着满满的讽刺意味啊。”三妹有点难过了起来。
“不过,也有人评论说,‘建议这个系列的文章多写啊,因为我花了半个月都没看懂《 Java 编程思想》中关于泛型的讲解,但再看完这篇文章后终于融会贯通了,比心。’”
“二哥,你能不能先说好消息啊?真是的。我也要给这位暖心的读者比心了。”三妹说完这句话就在我面前比了一个心,我瞅了她一眼,发现她之前的愁容也无影无踪了。
“那接下来,二哥还要继续写吗?”我看到了三妹深情的目光。
“嗯,我想该写集合了。”
“那就让我继续来提问吧,二哥你继续来回答。”三妹已经跃跃欲试了。
01、二哥,什么是集合啊?
三妹,听哥慢慢给你讲啊。
JDK 1.2 的时候引入了集合的概念,用来包含一组数据结构。与数组不同的是,这些数据结构的存储空间会随着元素增加而动态增加。其中,有一些集合类支持添加重复元素,而另一些不支持;有一些支持添加 null 元素,而另一些不支持。
可以根据继承体系将集合分为两大类,一类实现了 Collection 接口(见图 1),另一类实现了 Map 接口(见图 2)。
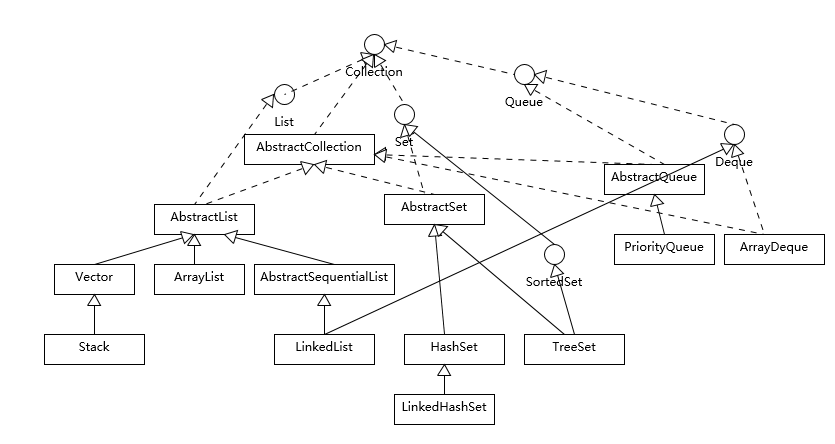
介绍一下图 1:
1)Collection 是所有集合类的根接口。
2)Set 接口的实现类不允许重复的元素,例如 HashSet、LinkedHashSet。
3)List 接口的实现类允许重复元素,可通过 index 访问对应位置上的元素,例如 LinkedList、ArrayList。
4)Queue 接口的实现类允许在队列的尾部或者头部增加或者删除元素,例如 PriorityQueue。
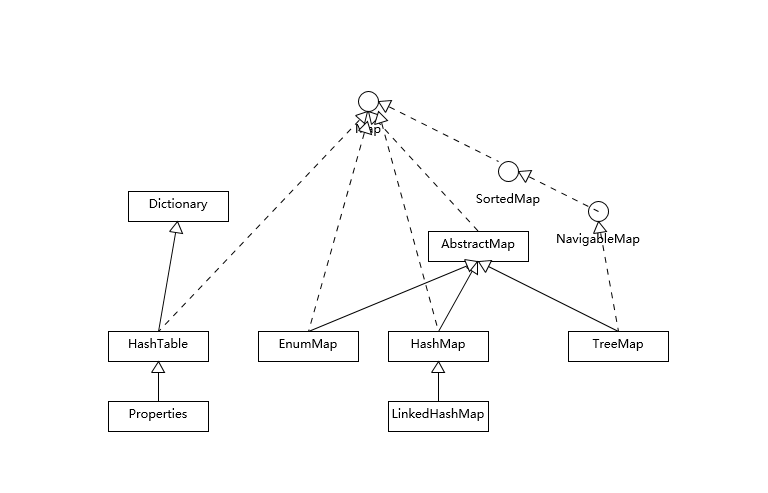
介绍一下图 2:
1)HashMap 是最常用的 Map,可以根据键直接获取对应的值,它根据键的 hashCode 值存储数据,所以访问速度非常快。HashMap 最多只允许一条记录的键为 null (多条会覆盖);但允许多条记录的值为 null。
2)TreeMap 能够把它保存的记录根据键(不允许键的值为 null)排序,默认是升序,也可以指定排序的比较器,当用迭代器(Iterator)遍历 TreeMap 时,得到的记录是排过序的。
3)Hashtable 的键和值均不允许为 null,是线程同步的,也就是说任一时刻只有一个线程能写 Hashtable,线程同步会消耗掉一些性能,因此 Hashtable 在写入时花费的时间也会比较多。
4)LinkedHashMap 保存了记录的插入顺序,当用迭代器(Iterator)遍历 LinkedHashMap 时,先得到的记录肯定是先插入的。键和值均允许为 null。
有了集合的帮助,程序员不再需要亲自实现元素的排序、查找等底层算法了。另外,基于数组实现的集合类在频繁读取时性能更佳,比如说 ArrayList;基于队列实现的集合类在频繁增加、更新、删除数据时效率更高,比如说 LinkedList;程序员所要做的就是,根据业务需要选择适当的集合类,至于性能调优嘛,可以微信找二哥。
02、二哥,LinkedList 和 ArrayList 有什么区别啊?
三妹,刚提完问题就打盹啊,继续听哥给你慢慢讲啊。
LinkedList 其实是一个双向链表,来看源码。
public class LinkedList<E>
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
1)LinkedList 包含一个非常重要的内部类——Node。Node 是节点所对应的数据结构,item 为当前节点的值,prev 为上一个节点,next 为下一个节点——这也正是“双向”链表的原因。first 为 LinkedList 的第一个节点,last 为最后一个节点。
2)size 是 LinkedList 的节点个数。当往 LinkedList 添加一个元素时,size+1,删除一个元素时,size-1。
ArrayList 其实是一个动态数组,来看源码。
public class ArrayList<E>
{
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
}
1)elementData 是 Object 类型的数组,用来保存添加到 ArrayList 中的元素。如果通过默认构造参数创建 ArrayList 对象时,elementData 的默认大小是 10。当 ArrayList 容量不足以容纳全部元素时,就会重新设置容量,新的容量 = 原始容量 + (原始容量 >> 1)(参照以下代码)。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
elementData = Arrays.copyOf(elementData, newCapacity);
}
>> 运算符还没有驾驭了。不过,通过代码测试后的结论是,当原始容量为 10 的时候,新的容量为 15;当原始容量为 20 的时候,新的容量为 30。
2) size 是 ArrayList 的元素个数。当往 ArrayList 添加一个元素时,size+1,删除一个元素时,size-1。
由于 LinkedList 和 ArrayList 底层实现的不同(一个双向链表,一个动态数组),它们之间的区别也很一目了然。
关键点1 :LinkedList 在添加(add(E e))、插入(add(int index, E element))、删除(remove(int index))元素的性能上远超 ArrayList。
为什么呢?先来看 ArrayList 的相关源码。
// ensureCapacityInternal() 方法内部会调用 System.arraycopy()
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
观察 ArrayList 的源码,就能够发现,ArrayList 在添加、插入、删除元素的时候,会有意或者无意(扩容)的调用 System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length) 方法,该方法对性能的损耗是非常严重的。
再来看 LinkedList 的相关源码。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
return element;
}
LinkedList 不存在扩容的问题,也不需要对原有的元素进行复制;只需要改变节点的数据就好了。
关键点2:LinkedList 在查找元素时要慢于 ArrayList。
为什么呢?先来看 LinkedList 的相关源码。
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
观察 LinkedList 的源码,就能够发现, LinkedList 在定位 index 的时候会先判断位置(是在 1 / 2 的前面还是后面),再从前往后或者从后往前执行 for 循环依次找。
再来看 ArrayList 的相关源码。
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
ArrayList 直接根据 index 从数组中取出该位置上的元素,不需要 for 循环遍历啊——这样显然更快!
03、二哥,HashMap 和 TreeMap 有什么区别啊?
三妹,提问题越来越有艺术了啊?继续听哥给你慢慢讲啊。
HashMap 存储的是键值对,其键是一个哈希码(Hash 的直译,也称作散列)。来看源码。
public class HashMap<K,V>
{
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
}
1)table 是一个 Node 数组,而 Node 是一个单向链表(只有 next)。HashMap 的键值对就存储在 table 数组中。
2)loadFactor 就是大名鼎鼎的加载因子,默认的加载因子是 0.75, 据说这是在时间和空间成本上寻求的一种折衷。
3)initialCapacity 就是初始容量,默认为 16。
4)threshold 是 HashMap 的阈值——判断是否需要对 HashMap 进行扩容,threshold 的值 = 容量 * 加载因子,当 HashMap 中存储的数据数量达到 threshold 时,就需要将 HashMap 的容量加倍。
“初始容量” 和 “加载因子”对 HashMap 的性能影响颇大。容量是 HashMap 中桶(见下图)的数量,初始容量只是 HashMap 在创建时的容量。加载因子是 HashMap 在其容量自动增加之前可以达到多满的一种尺度。
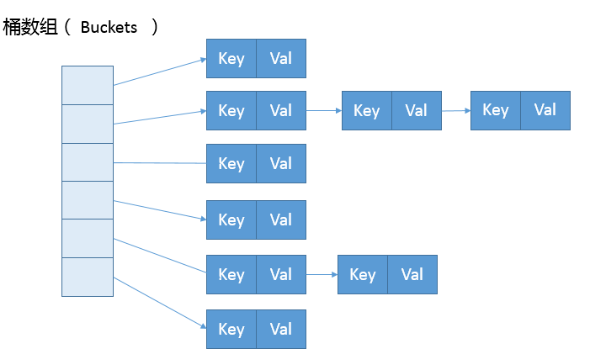
TreeMap 存储的是有序的键值对,基于红黑树(Red-Black tree)实现。可以在初始化的时候指定键位的排序方式,如果没有指定的话就根据键位的自然顺序进行排序。来看源码。
public class TreeMap<K,V>
{
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
private static final boolean RED = false;
private static final boolean BLACK = true;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
}
1)root 是红黑树的根节点,是一个 Entry 类型(按照 key 进行排序),包含了 key(键)、value(值)、left(左边的子节点)、right(右边的子节点)、parent(父节点)、color(颜色)。
2)comparator 是红黑树的排序方式,是一个 Comparator 接口类型,该接口里面有一个 compare 方法,有两个参数 T o1 和 T o2,是泛型的表示方式,表示待比较的两个对象,该方法的返回值是一个整形, o1大于o2,返回正整数; o1等于o2,返回0;o1小于o3,返回负整数。
总结一下就是,HashMap 适用于在 Map 中插入、删除和定位元素;TreeMap 适用于按自然顺序或自定义顺序遍历键(key)。
04、二哥,再讲讲二分查找呗!
三妹,没有任何问题,包在我身上。不过,在讲之前,你能先去给哥泡杯咖啡吗?
通常,我们从数组中查找一个元素时,需要对整个数组进行遍历。但如果这个数组是排序过的,就可以进行二分查找了。
二分查找的方式:
第一步,将数组中间位置上的元素与要查找的对象进行比较,如果两者相等,则查找成功;否则进行第二步。
第二步,利用中间位置将数组分割成前、后两个子集。
第三步,比较要查找的对象与中间位置上的元素,如果前者大于后者,则在后面的子集中按照之前的方式进行查找;否则,在前面的子集中按照之前的方式进行查找。
这样做可以将查找范围缩减一半,大大的减少了查询的次数。
Collections 类的 binarySearch() 方法实现了二分查找这个算法,可以直接使用,前提是先要排序,否则将返回 -2。源码如下。
private static <T>
int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
我们来测试一下。
List<String> list1 = new ArrayList<>();
list1.add("沉");
list1.add("默");
list1.add("王");
list1.add("二");
Collections.sort(list1); // 先要排序
System.out.println(Collections.binarySearch(list1, "王")); // 2
05、故事的未完待续
“二哥,终于讲完《集合》了,喝口咖啡吧!”三妹的态度很体贴。
“谢谢。”
“二哥,如果这篇文章继续遭受到批评,你会不会气馁啊?”三妹眨了眨眼睛,继续问我,我看到她长长的睫毛,真的很美。
“嗯,对于作者来说,当然希望文章能够得到正面的反馈,如果是负面的反馈,那也在我的意料之中。”
“为啥?”三妹很好奇。
“《教妹学 Java》是一种创新的写作手法,市面上还没有,新鲜、有趣的事物总需要一段时间才能被大众接受,否则也就不叫创新了。”
“二哥,为你的勇气点赞!”看到三妹很为我骄傲的样子,我的心里盛开了一朵牡丹花。
上一篇:教妹学 Java:晦涩难懂的泛型
谢谢大家的阅读,原创不易,喜欢就随手点个赞👍,这将是我最强的写作动力。如果觉得文章对你有点帮助,还挺有趣,就关注一下我的公众号「沉默王二」。

(转载本站文章请注明作者和出处 沉默王二)